日志数据是一种广泛可用的数据资源,用于记录各种软件系统中运行时的系统状态和关键事件。开发人员通常利用日志数据来获取系统状态、检测异常和定位根本原因。隐藏的丰富信息为分析系统问题提供了一个很好的视角。因此,通过在大量日志数据中挖掘日志信息,结合数据驱动的方法,可以帮助增强系统的健康、稳定性和可用性。
01. 日志解析介绍
随着现代计算机系统规模和复杂性的增加,日志数据呈爆炸式增长。衍生出了大量数据驱动的方法,以满足日志自动检测异常的需求。
1)日志异常检测流程
在异常检测之前,需要对日志数据进行收集、解析、特征提取等处理。
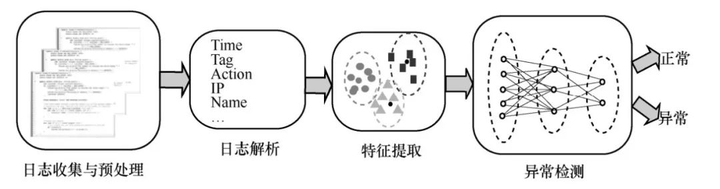
① 日志收集与预处理
首先需要获取原始日志数据并进行预处理。日志收集主要指从设备中获取相关日志记录,包括系统的运行状态、时间信息等,这些信息用来记录系统运行过程中的重要信息,是日志分析的前提。预处理主要是根据具体需求,将日志数据中的无效信息进行剔除,包括重复信息、无用信息等。日志信息中的事件序列如图:
② 日志解析
第二步是日志的解析,对处理后的数据进行解析,分析日志结构与信息,获取日志针对每个事件的模板。日志解析是从无结构的日志中提取相应的事件模板,每个模板由多个指定参数构成,作为后续特征提取的基础。
③ 特征提取
通过设定固定的时间范围作为窗口,对窗口内日志内容进行解析,提炼其中的事件模板,将日志切分成一组日志事件序列 log,进而从提取信息中选择合适的变量和分组来表示相关内容,并进行数字化向量表示,构建成特征向量,方便后续进行机器学习。
实际解析中,可以将不同服务器的操作进行关联分析,获得更多的异常信息。例如,针对服务器 "zookeeperserver" 构建特征向量<2,1,1, …>,表示事件1 "server environment" 发生2次,事件 "client attempting to establish new session" 、 "established session" 各发生 1 次。最终,可以由不同时间段形成的特征向量构建成特征矩阵。
其中,日志数据的解析是后续异常分析的重要基础。
2)日志数据解析方法
日志本身是对一系列系统或应用中发生的事件进行记录,一个记录通常代表一个事件发生的相关具体内容,日志记录通常包含但不限于事件的时间、源头、标签、信息等。通过一些机器学习的方法可以对其中的详细信息进行解析。以下是几种常见的基于机器学习的日志解析技术:
① 基于聚类的数据挖掘方法:
主要通过计算对日志进行聚类,进而进行数据挖掘,形成事件模板,完成对日志的解析。
② 基于自然语言处理的解析方法:
使用自然语言处理对日志进行解析。首先,将文本划分为单词进行标记;然后,对单个单词进行词干分析、同义词替换、停用词删除等;之后,将单词列表中的句子转化为矢量表示形式,之后运用一些无监督聚类算法进行分类。
③ 文本相似度计算方法:
通过对文本相似度进行计算,合并类似模板,实现快速日志解析,例如:利用最长公共子序列算法(lcs)以流方式解析日志。
02. 日志异常检测
在完成日志数据的解析之后,就需要通过日志异常检测,来对系统运行情况进行判断,辅助运维人员进行运维工作。
常见的日志异常检测方法可以分为有监督和无监督两种,如聚类分析、决策树等。例如,在将日志信息标记为正常、 异常后,根据提取的特征进行聚类分析。首先对各个特征赋予不同权重;然后将特征向量进行归一化处理;之后定义特征向量之间的相似性(即距离大小);最后对日志间的相似性进行判断,定义是否为异常。针对异常检测结果,进一步进行人工分析和确认,结果可以作为样本加入数据集中,对模型进行修正。
近年来也发展出了许多基于深度学习的方法,如基于lstm的深度学习方法等。通过对特征向量进行学习,对输入特征矩阵机器学习模型进行训练,从而生成一个异常检测模型,并使用该模型对新的日志进行检测。
1)监督学习方法
一种从标记的训练数据中得出模型的机器学习方法。带标签的训练数据(通过标签指示正常或异常状态)是监督异常检测的先决条件,训练数据标签越多,模型越精确。在基于日志的异常检测方面使用的机器学习方法较为宽泛。例如:logclass,这种方法首先预处理设备日志,并产生词描述方法的矢量,然后通过机器学习方法(例如:svm)来训练异常检测和分类模型,最后进行在线异常检测。还有一些其他方法,利用一些常见的机器学习模型如:逻辑回归、knn算法等进行日志异常检测。
2)无监督学习方法
无监督学习方法指没有任何标记的训练数据情况下得到模型的机器学习方法。常见的无监督方法包括各种聚类方法、关联规则挖掘、基于主成分分析等。
① 聚类方法
方法思想:通过分析日志特点,把日志划分为不同的分组,组内的日志相似度越大越好,组间的日志相似度越小越好。计算日志间相似度,根据相似度用相应的方法把日志分成不同的类,最后提取日志模板。例如,logcluster和log2vec是两种较为典型的异常检测方法。
logcluster:
是一种将日志聚类来进行日志问题识别的方法。首先将每个日志序列通过一个向量表示,然后计算两个日志序列之间的相似度值,并应用聚集层次聚类技术将相似的日志序列分组为聚类。
log2vec:
是一种基于异构图嵌入的威胁检测方法。首先,根据日志条目之间的关系 将其转换为异构图;然后使用改进图嵌入方法,可以自动将每个日志描述为一个低维的向量;最后,通过检测算法,可以将恶意日志和良性日志进行聚类,识别出恶意行为。
② 关联规则挖掘
例如:通过最长公共子序列(lcs)方法将日志解析为数组。然后,使用时间关联分析(tca)将相似事件聚类,找出操作的关键事件。最后,根据标记进行异常检测。
除此以外还有其他的日志异常检测方法,如基于主成分分析法(pca)。
3)深度学习方法
利用卷积神经网络(cnn)的优势,可以有效地提取并行方式中的空间特征,并通过长短期记忆(lstm)网络来捕获顺序关系。例如:
① deeplog
是主要使用长短期记忆的神经网络模型,将系统日志建模为自然语言序列。deeplog 从正常执行中自动学习日志模型,并通过该模型, 对正常执行下的日志数据进行异常检测。
② swisslog
该方法主要包括两个阶段,即离线处理阶段和在线处理阶段。每个阶段包括日志解析、句子嵌入、模型训练阶段,在线阶段还包括异常检测阶段。
- 日志解析部分对历史日志数据进行分词、字典化和聚类,提取多个模板,这些日志语句与相同的标识符联系起来构建日志序列,然后将日志序列转化为语义信息和时间信息。
- 句子嵌入部分使用bert模型或word2vec模型对句子进行编码,转化为词向量。
- 模型训练阶段,将这些语义信息和时间信息输入到神经网络模型中学习正常、异常的日志序列的特征。
除上述方法外,还有基于文本特征建模,基于工作流,基于不变挖掘 (im)等其他异常检测方法。
03. 嘉为鲸眼日志中心
日志解析与异常检测和对日志数据价值发挥至关重要,企业通常也需要引入相应的工具,构建日志管理能力,确保日志数据发挥价值,保障业务的平稳运行。
嘉为鲸眼日志中心集成了日志智能化聚类、智能化异常分析场景,基于日志异常检测能力,可以帮助it人员快速分析日志及识别异常,提升运维效率,为企业构建一站式日志管理平台,实现从采集至分析全流程统一日志管理,提升日志管理场景效能,提速排障最后一公里。
1)快速掌握日志全貌
千万日志数据聚合成十几种格式类型,提高信息密度,避免大量时间看重复数据。
2)敏锐捕捉动态异常
每种日志格式的日志量变化可视化,迅速清晰地观察日志异变。
3)动态配置监控策略
无需知晓和人工配置日志异常规则,自动根据特定格式的日志量统计来判断是否异常。
4)辅助定位代码级别的问题
日志聚类能将代码运行映射到日志展示,赋予运维通过日志探查故障的钥匙。
面向企业it研发和运维,满足分布式架构下海量日志采集及存储、检索及分析。基于业界主流的全文检索引擎,通过蓝鲸专属 agent 提供多种场景化日志采集,提供快速检索分析、辅助故障定位功能。产品具备五大优势,为客户提供日志管理场景价值。
5)方案优势
采集丰富:不同终端不同格式日志统一采集,采集过程中支持解析、脱敏、过滤,采集简单便捷;
推广便捷:内置常用组件的日志解析模板和仪表盘模板,且允许用户自建日志解析模板库,方便接入推广;
智能高效:融合蓝鲸海量数据分析底座和智能化组件,实现高效的日志智能聚类,智能异常检测和告警;
联动流畅:和监控告警体系打通,快捷配置日志关键字、日志指标告警,无需依赖跳转;
信创适配:已适配多种国产化设备和系统,也可完成对信创设备的采集。
6)客户价值
高效排障:联动蓝鲸基础监控告警,实现关键字、日志指标异常检测,告警通知,明细日志下钻,高效故障定位;
数据安全:提供完善的权限管控、数据隔离以及敏感数据能保护能力,保障数据安全,满足数据安全管理诉求;
成本优化:提供数据分层架构,按照冷、热数据分层,合理降低存储成本;
便捷推广:结合蓝鲸agent能力实现日志采集插件一键部署、批量安装、性能稳定。











